
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- 맛집
- 운영체제 강의
- 스크래치
- 프로그래밍
- list
- 직업으로서의 정치 서평
- concurrency
- xv6
- Deep Learning
- 푸드트럭
- 잘 짜인 코드
- Operating System
- 미국
- Snap!
- control flow
- 7월4일
- Scratch
- 균형의 정치
- Lock
- The beauty and Joy of computing
- scheduling policy
- insertion Sort
- 코딩
- Jupyter Notebook
- 여행
- 버클리
- 독립기념일
- CLRS
- Process
- 영어논문
- Today
- Total
여행다니는 펭귄
Swapping and Page Replacement Policy 본문
Operating System은 Virtual Space를 매우 크게 할당해 줍니다. 그것이 편리하고, 사용하기 쉽기 때문이죠.
그러니 저희는 Virtual Memory가 가득 차있을지, 아닐지 신경을 쓸 필요가 없는 것입니다.
그렇다면 만약 Virtual Memory를 다 쓰는 프로그램이 아주 많아서 메모리가 부족하면 어떻게할까요?
이를 위해서 OS는 Swapping 을 사용합니다.
Disk안에 Page Size의 Unit을 만들어 두고 계속해서 Swap in, Swap out 시키는 것이죠.
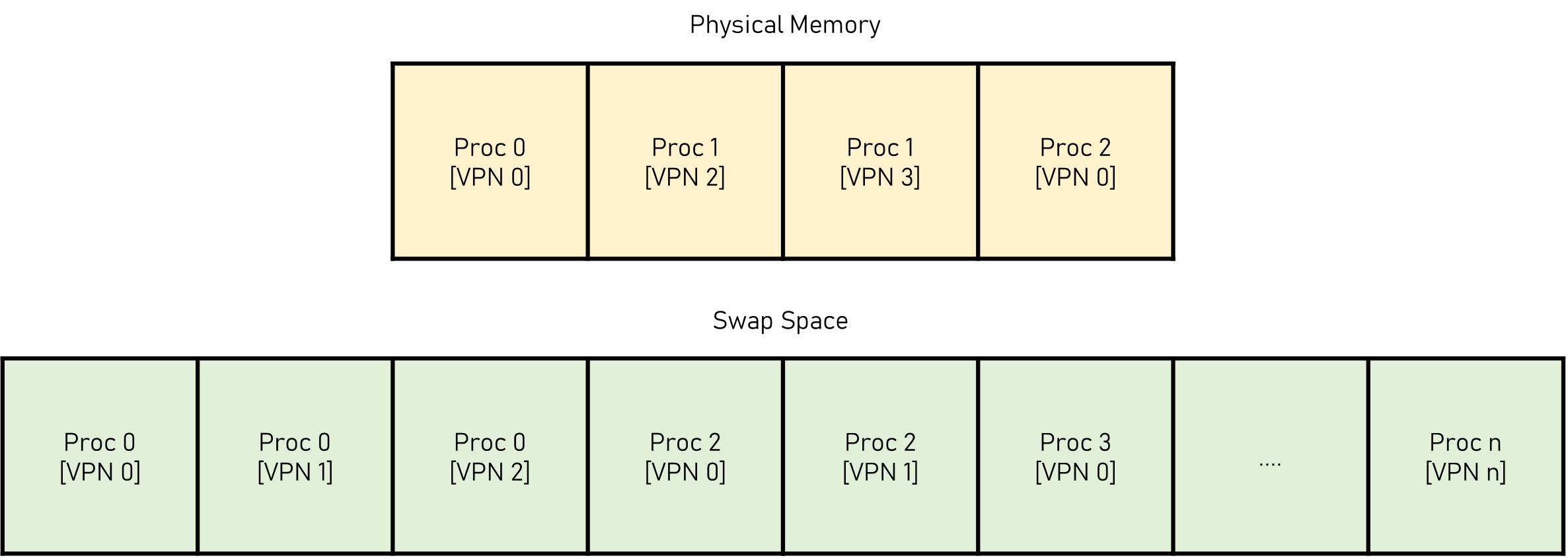
이럴 경우 Page Table에는 present bit가 추가됩니다. 그러니까 Memory에서 이것을 찾아야하는건지 Disk에서 찾아야 하는건지 알려주는 용도이죠.
Page Hit, Page fault는 이것이 Physical Memory에 각각 있을 경우, 없을 경우를 의미합니다.
그렇다면 Page fault는 어떻게 해결할까요?
- Page miss가 Page fault라는 Exception을 발생시킵니다.
- OS의 fault handler가 Victim을 Select 합니다.
- Victim을 Disk에 써 주고, Physical Memory에 Fault를 발생시킨 데이터를 써 줍니다.
- 다시 한번 요청을 하면 Page Hit이 나게 됩니다.
그럼 어떻게 Victim을 Select할까요? 만약 자주 쓰는 걸 Victim Select를 했다가는 Page fault의 비용이 매우 비싸기 때문에 성능에 Critical 한 영향을 미칠 것입니다. (Disk는 DRAM보다 10,000x배 느림)
Effective Access Time을 통해서 Page fault가 영향을 얼마나 줄지 한번 봐 보도록 할까요?

진짜 엄청난 영향을 주죠?
그럼 어떻게 Page fault를 줄일 수 있을까요?
일단 전에도 언급했듯이 정보에는 Locality가 있기 때문에 page fault는 생각보다 덜 발생하게 됩니다. 이 Locality를 얼마나 잘 살리느냐가 바로 Replacement Policy의 핵심입니다.
참고로 언제 Replacement가 일어날까요?
Page가 가득 찼을때 할까요? 실제로는 아주 약간의 memory를 늘 free 상태로 유지하고 있습니다.
이를 Swap Daemon이라고 하는데요, free space에 High Watermark와 Low Watermark를 지정하여서, 빈 공간이 줄어 LW에 도달하게 되면 Swap Daemon이 Page를 쫓아내서 HW까지 빈 공간이 늘어나도록 만든 후 멈춥니다.
이제 Replacement Policy를 봅시다 OS는 Memory에게 누구를 갈아 끼울지를 결정하는데, 이를 결정하는 Policy가 바로 Replacement policy 입니다.
가장 간단한 Policy는 FIFO입니다. 가장 먼저 들어온 것을 내보내는 것이죠.
이것은 얼마나 자주 사용되는지를 고려하지 않는 방식이라 비효율적입니다.
또한, Cache가 늘어날수록 Hit rate는 올라가야하는데 FIFO는 증가하기도 합니다. 이것은 Belady's anomaly라고 불리는 현상입니다.
또 하나의 방법은 Random 입니다. Random은 종종 Optimal hit rate에 가까워질정도로 좋아지기도 합니다.
여기까지가 History 없이 Victim을 Select하는 방법이었고 LRU(Recency), LFU(Frequency)는 history를 고려하는 방법입니다.
그렇다면 이것들이 각각의 Worklord에서 어떻게 동작할지를 한번 살펴볼까요?
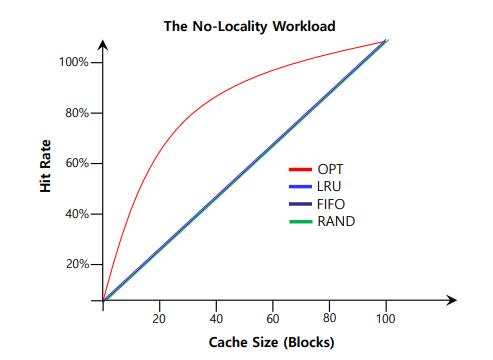
Locality가 없기 때문에 Optimal 한 경우를 제외하면 그 어떠한것도 의미가 없습니다.
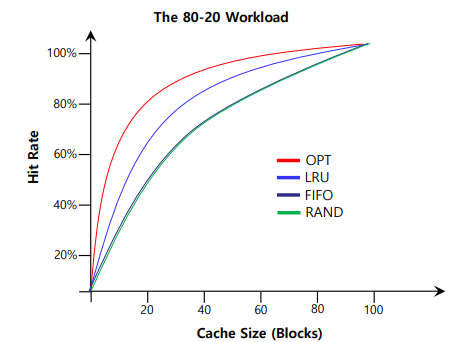
Locality가 존재할 경우 LRU가 제일 자주 쓰이는 Page들을 보관하기 때문에 제일 성능이 좋습니다.

만약 1~50 이라는 데이터를 Loop로 반복해서 넣는 경우 LRU나 FIFO는 Locality를 보장할 수 없습니다.
이제 LRU를 구현하는 방법에 대해서 알아볼까요?
- Counter 사용하기
- 페이지에 Reference할 때마다 시간을 Counter에 저장해 줍니다.
- 제일 작은 Counter를 찾아 페이지를 제거합니다.
- 단점은 Search through를 해 주어야 한다는 것입니다.
- Stack 사용하기
- Page가 Reference되면 Stack의 제일 상단으로 옮겨줍니다.
- 장점은 Search through를 해줄 필요가 없다는 것입니다.
- 단점은 Update를 해주는 것이 비싸다는 것입니다.
- Page가 Reference되면 Stack의 제일 상단으로 옮겨줍니다.
- Clock Algorithm사용하기
- Hardware의 Support가 필요합니다.
- Page가 Reference되면, Reference bit가 1로 바뀝니다. (HW)
- 하드웨어는 절대 이 bit를 0으로 바꾸지 않고 OS가 바꾸도록 해 줍니다.
- 모든 페이지는 circular list로 system에 의해 arrange됩니다.
- clock의 시침이 시작할 페이지를 가리키고 있습니다.
- Page replacement가 요구될때 돌면서 victim을 select할지 말지 결정합니다.
- bit가 0이면 victim이 됩니다.
- bit가 1이면 0으로 만들고 다음 page로 돕니다.
- 이 경우 LRU만큼 성능이 뛰어나지는 않습니다.
- Hardware의 Support가 필요합니다.
LRU가 아니라 다른 알고리즘을 Implement할 때 고려되는 것들도 있습니다.
- Dirty Page
- HW가 modified bit(= dirty bit)를 포함해 줍니다.
- 이것은 Page가 수정되었다는 의미로, evict하려면 Disk에 다시 Write해 주어야 합니다.
- 고로, 비용이 싼 Clean Page가 Victim이 됩니다.
- Dirty Page를 Disk에 기록하는 순간은 Dirty Page를 많이 모아 pending wirte가 될때 한번에 써 주는 것입니다. 그러면 IO를 최소화 할 수 있습니다.
- Page를 Memory에 언제 불러올까요?
- Demand : 요구 될 때 불러옵니다.
- Prefetching : 미리 예상하여 불러옵니다.
- Thrashing
- 메모리가 과하게 Subscribed 되었을때 즉, Running Process가 요구하는 memory의 양이 physical 메모리를 초과하였을때 발생합니다.
- Subset of Process를 돌리지 않도록 결정합니다. 즉 돌아가는 Set of Process를 줄여줍니다.
'컴퓨터 > 운영체제' 카테고리의 다른 글
| FSCK and Journaling (0) | 2021.12.15 |
|---|---|
| Fast File System (0) | 2021.12.14 |
| Paging with Smaller Tables (0) | 2021.12.14 |
| Translation Lookaside Buffer (0) | 2021.12.12 |
| Paging (0) | 2021.12.12 |


