
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 운영체제 강의
- 프로그래밍
- Deep Learning
- list
- 푸드트럭
- Jupyter Notebook
- insertion Sort
- Lock
- 여행
- 스크래치
- The beauty and Joy of computing
- concurrency
- 영어논문
- CLRS
- 7월4일
- 맛집
- 코딩
- xv6
- Scratch
- 버클리
- Snap!
- Process
- 미국
- Operating System
- 잘 짜인 코드
- control flow
- 균형의 정치
- 직업으로서의 정치 서평
- 독립기념일
- scheduling policy
- Today
- Total
여행다니는 펭귄
HDD란? 본문
Hard Disk Drive
Hard Disk Drives, Disk Scheduling, RAID
Hard Disk Drive

하드 디스크는 실제로 디스크로 이루어져있고 이 디스크를 돌리면서 Arm으로 데이터를 읽는 구조입니다.
구체적인 구조를 한번 볼까요?
이것은 HDD안의 Platter 입니다. Plater은 두개의 Surface를 앞뒤로 가지고 있죠.
각 Surface는 동심원들로 이루어져 있는데 이를 Track이라고 부릅니다.
Track은 gap으로 구분되는 Sector로 이루어져 있고 이 Sector에 데이터를 저장하게 됩니다.
그럼 정보는 어떻게 Read/Write 할까요?
- Surface는 track으로 이루어져있고 track은 Sector로 이루어져 있습니다.
- Disk platter들은 반 시계방향으로 움직입니다
- Arm의 Head는 적당한 Track을 찾기 위해 앞뒤로 움직입니다
- Head가 Track에 도착하면 Surface가 도는 동안 Controller가 정보를 읽습니다.
여기서 알 수 있는 사실은 정보를 찾는 과정에서 Delay가 발생한다는 것입니다.
만약 저희가 위 그림과 같이 Blue Sector를 읽고 Red Sector를 그다음에 읽으려 한다면
그 사이에 Seek Time이 또 발생할 것입니다.
이런 것을 고려하여 Disk Access Time은 어떻게 구할 수 있을까요?
- Seek time : 헤드가 알맞은 Track으로 가는데 걸리는 시간
- 3~9 ms정도 걸림
- Rotational latency : 헤드가 알맞은 Sector로 가는 시간
- T avg rotation = (1/2) x (1/RPMs) x (60 sec/1 min)
- Typical rotation 은 7200 RPMs 정도 됩니다.
- Transfer time : Target Sector를 읽는데 걸리는 시간
- T avg transfer = (1/RPMs) x 1/(avg # sectors/track) x 1/(avg # sectors/track)
을 더한 값이 바로 Disk Acces Time이 됩니다.
한번 실제로 구해 볼까요?
- Given :
- Rotational rate = 7200 RPM
- Average seek time = 9 ms
- Avg# sector/track = 400
- Calculate :
- T avg rotation = 1/2 x (1/7200) x 60(sec) = 0.004 sec = 4ms
- T avg transfer = 1/7200 x (1/400) x 60(sec) = 0.00002 sec = 0.02 ms
- Disk Access Time = 9ms + 4ms + 0.02ms
- Important points :
- Access time은 Seek Time과 Rotational latency가 Dominant 합니다
- 그러니까 첫번째 bit를 찾는데 비용이 많이 들고 읽는 것은 매우 쉽다는 것이죠
- SRAM은 4ns/doubleword 가 걸리고 DRAM은 60ns/doubleword가 걸리므로 Disk는 매우 느리다고 할 수 있습니다. (각 40,000배와 2,500배 정도 느림)
그럼 이것을 어떻게 Logical Disk Block으로 나타낼까요?
현대 아키텍쳐에서 매우 복잡한 Disk던, SSD던 간단하고 추상화된 Array로 저장공간을 표현합니다.

이 Logical Block으로 Mapping을 해주는 것은 Device 내부의 Firmware가 해줍니다. HDD로 예시를 들면 (Surface, track, sector) 로 변환이 되겠죠?
그렇다면 어떻게 Mapping하는 것이 좋을까요?
가까운 Sector를 Logical Block에서도 가깝도록 mapping해주는 것이 좋을 것입니다.
이렇게 구현하면 I/O access의 지역적인 특성을 나타내기 편합니다.
만약 Bad Sector가 나타난다면 Bad Sector와 인접한 섹터에 같은 Logical Block으로 map을 넘겨줍니다.
다만 이것은 I/O의 성능 저하 가능성이 있습니다.
Disk Scheduling
Accesss time을 어떻게 해야 줄일 수 있을까요?
이는 Seek Time과 Rotational Latency를 줄여야 한다는 의미입니다.
일단 I/O Request가 어떻게 동작하는지 살펴볼까요?
I/O Request는
Read할지 Write 할지
데이터를 올릴 Memory address
데이터를 가져올 Disk address (offset)
Number of sectors to transfer (length)
로 이루어져 있습니다.
이 Requests들은 즉시 처리되기도 하지만 만약 다른 Request가 있을 경우 I/O Queue에 저장됩니다.
이 I/O Queue를 어떤 순서로 처리할 것인지를 정하는 것이 바로 Disk Scheduling 입니다.
- FCFS : First Come 한것을 First Serve하는 모델로 제일 간단합니다.
- SSTF : Shortest Seek Time First로 가장 Seek Time이 작은것을 먼저 처리합니다.
- SJF CPU Scheduler처럼 몇몇 Seek Time이 멀 것으로 예상되는 바깥쪽 트랙에 대해서 Starvation문제를 일으킵니다.
- SCAN : 다른 말로 Elevator Algorithm이라고도 하며, 한 방향으로만 쭉 갔다가, 다른 방향으로 다시 쭉 가는 알고리즘입니다.
- 만약 request가 새로 queue에 도착했는데 현재 Head의 위치와 가깝다고 하더라도 반대의 Direction을 가진다면 매우 오래 기다리게 된다는 문제가 있습니다.
- 응답 시간이 양 끝이 가운데보다 느려 일관성이 없습니다.
- C-SCAN: 한 방향으로 가기는 하는데, 방향의 끝에 도달하면 바로 처음으로 돌아가서 같은 방향으로 갑니다, 즉 반대 방향으로는 절대 움직이지 않습니다.
- 주목할 점은 중간에 들어오는 요청이 있어도 무시한다는 점입니다.
다음 중 어떤 Scheduling 알고리즘을 구할지는 tpye과 number of requests에 의해 결정됩니다.
- SSTF는 간단하고 자연스럽습니다
- SCAN과 C-SCAN은 Disk의 작업량이 몹시 많은 프로그램에 사용됩니다. Starvation 문제가 적기 때문이죠.
RAID
저희는 Disk를 한개만 놓고 보는것이 아닌 Array of Disk로 봅니다. RAID는 이 Disk중 어떤 것들에 접근할지 계산해줍니다.
RAID의 평가 기준은 다음과 같습니다.
- Reliability : 얼마나 많은 Disk faluts를 복원할 수 있는지
- Capacity : 얼마나 많은 용량을 시스템이 사용할 수 있는지
- Performance
그럼 RAID의 종류에 대해서 살펴볼까요?
- RAID 0
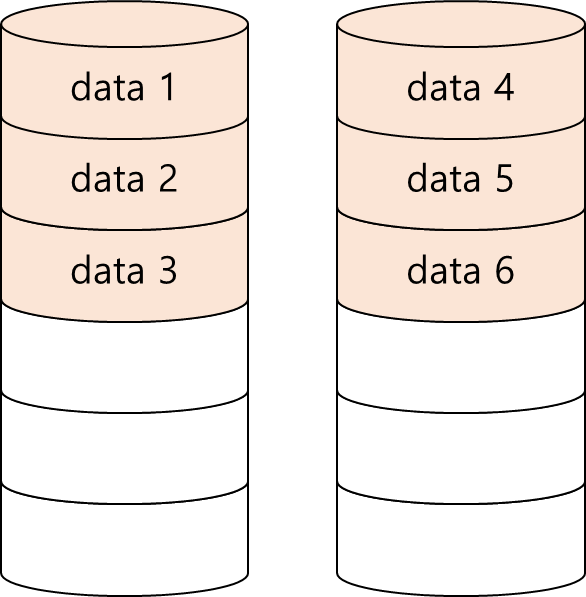
- RAID 0은 모든 DISK를 각각 다른 정보를 저장하는데 사용합니다.
- Parity 정보나, 중복된 데이터 저장이나, 복원에 대한 정보는 전혀 저장되지 않습니다.
- 장점 : Performance & Space efficiency (Capacity, Performance)
- Space를 전부 사용하므로 Space efficiency값은 1입니다.
- 단점 : high failure rate (Reliability)
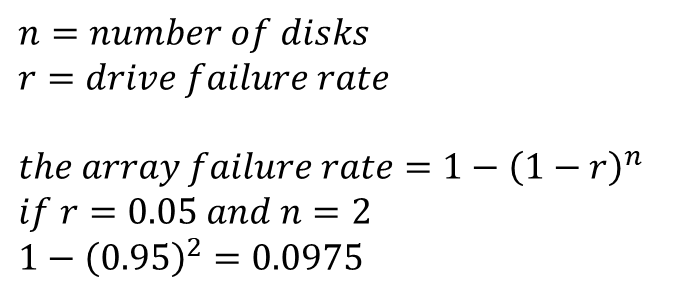
- 장점 : Performance & Space efficiency (Capacity, Performance)
- RAID 1
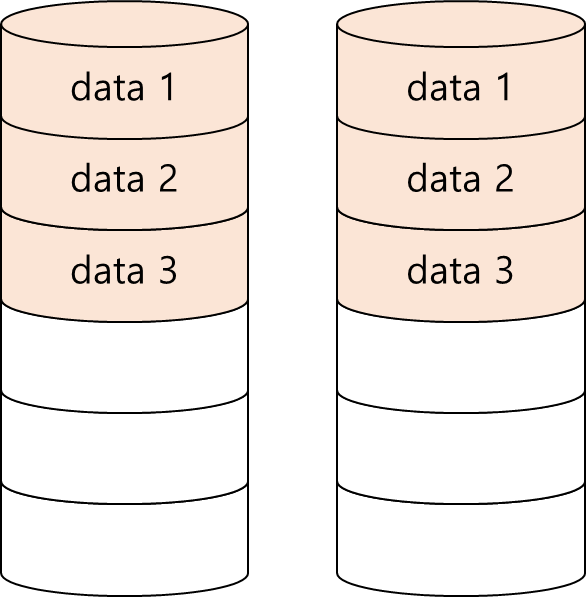
- RAID1은 완전히 같은 copy data를 저장합니다. 극단적으로 n개의 RAID 1 Disk가 있다면 1개 빼고 전부 Copy Data를 저장합니다.
- Array는 가장 작은 member의 disk 까지만 커질 수 있습니다.
- 장점: Low failure rate(Reliability)

- 단점: Capacity & Performance

- RAID 4

- RAID 4는 3개의 n-1개의 저장 블록과 한개의 parity block으로 나눕니다.
- 장점: Relatively high (Reliability, Performance, Capacity)

- 장점: Relatively high (Reliability, Performance, Capacity)
- RAID 4는 3개의 n-1개의 저장 블록과 한개의 parity block으로 나눕니다.
- RAID 5
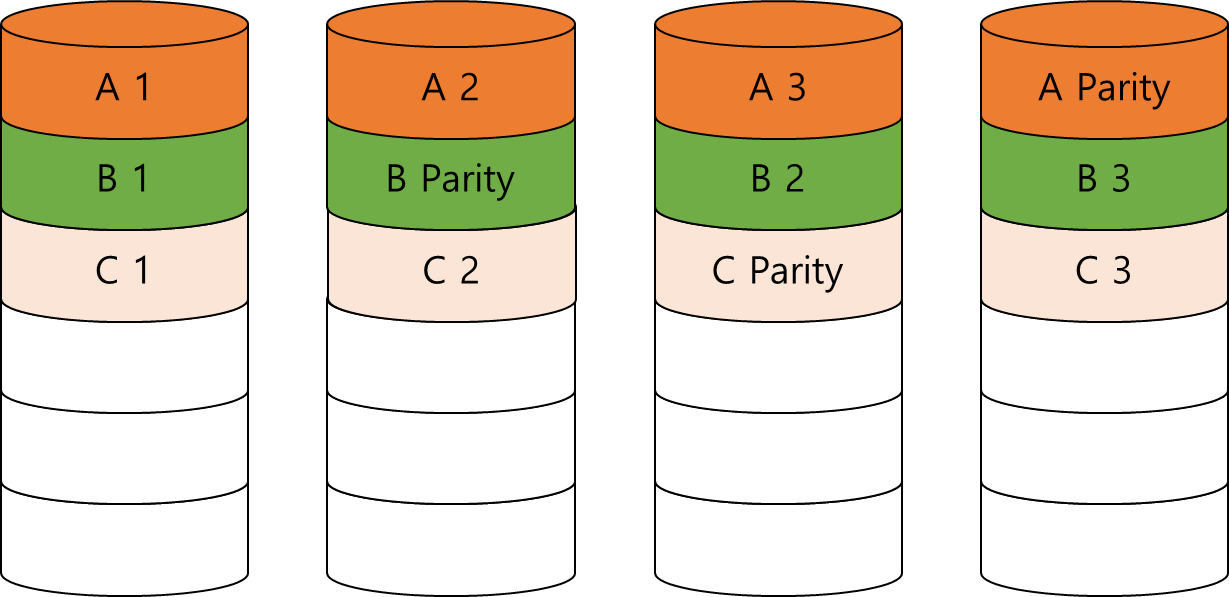
- RAID 5는 RAID 4와 다르게 Parity 전용 Disk 공간을 분리하여 두지 않습니다.
- 더 나은 Random performance를 보입니다.
- Parity Disk가 병목에 걸리지 않습니다.
- RAID 5는 RAID 4와 다르게 Parity 전용 Disk 공간을 분리하여 두지 않습니다.
- RAID 6

- RAID 6은 RAID 5에 Parity bit를 한개 더 쓰는 것입니다.
- RAID 5 보다 failure rate가 낮습니다.
- 그렇지만 Parity bit를 두개 연산해야 하므로 Performance penalty가 있습니다.
- 최근 시스템의 제일 유명한 방식입니다.
- RAID 6은 RAID 5에 Parity bit를 한개 더 쓰는 것입니다.
'컴퓨터 > 운영체제' 카테고리의 다른 글
| I/O , File 과 Directory 측면에서 (0) | 2021.12.10 |
|---|---|
| Flash-based SSD (0) | 2021.12.10 |
| I/O Devices (0) | 2021.12.09 |
| Free Space Management (0) | 2021.12.08 |
| Virtual Memory and Adress Translation (0) | 2021.11.29 |



