
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- scheduling policy
- Jupyter Notebook
- 푸드트럭
- 맛집
- 버클리
- list
- 여행
- Snap!
- 잘 짜인 코드
- xv6
- 스크래치
- Scratch
- 미국
- Deep Learning
- control flow
- 운영체제 강의
- CLRS
- concurrency
- 균형의 정치
- 영어논문
- Operating System
- 프로그래밍
- Lock
- 직업으로서의 정치 서평
- The beauty and Joy of computing
- 독립기념일
- 7월4일
- 코딩
- insertion Sort
- Process
- Today
- Total
여행다니는 펭귄
Flash-based SSD 본문
SSD란 뭘까요?
Solid State Storage Drives는 mechanical(moving parts)한 부분이 없습니다.
그래서 HDD보다 응답시간이 빠르고, 작업을 처리하는 양도 더 많죠.
다만 DRAM과는 다르게 파워가 끊겨도 정보가 손실되지 않습니다.
이 SSD의 핵심 기술이 바로 NAND flash memory 입니다.
NAND Flash는 electronic circuits를 사용하여 read와 write 할 수 있는 특성을 가집니다.
Floating Gate Transistor를 쓰기 때문에 파워가 없어져도 값을 유지 가능하다는 특성이 있습니다.
SSD는 어떻게 동작할까요?
SSD는 세개의 Operation을 통해 관리되고, 각 셀의 초기상태를 1이라고 부릅니다.
- Program : value를 0으로 바꿔줍니다.
- Erasure : value를 1로 바꿔줍니다.
- Read : 어떤 값이 저장되어 있는지 읽을 수 있습니다.

이는 구체적으로는 Vth(Threshold Voltage)를 높이고 낮춤으로써 동작합니다.
NAND Flash Memory의 구성 요소는 무엇일까요?
일단 기본 단위인 Cell이 존재합니다.
Cell들이 모여 Page라는 단위를 이루며, Page내부에 있는 Cell들은 동시에 읽혀지고 쓰여집니다.
Page들이 모여 Block이라는 단위를 이루며, 뭔가 지우는 연산을 할때 Block채로 지워집니다.
- 각 세밀한 부분을 update하는 In-place update와 같은것은 support 되지 않습니다.
- 정보를 쓰기 전에는 전부 블록 단위로 지워야 합니다.
그래서 이 Block들이 NAND flash die를 구성하며, 두개에서 네개의 dies 들이 한개의 NAND Chip이 됩니다.
이렇게 구성된 NAND Flash Chip의 성능은 다음과 같이 요약됩니다.
- Read는 Write보다 10배가량 빠릅니다
- Erasure이 제일 느립니다
- Throughput(처리량)이 매우 높습니다
어떻게 하면 성능을 올릴 수 있을까요?
속도를 올리려면 많은 NAND Chip들을 합치고 그들을 parallel하게 접속하는 것이 하나의 방법이 될 수 있습니다.
이 작업은 SSD controller(in Embedded System) 에 의해 이루어집니다.
용량을 늘리려면, Multi level cell이라는 technology를 사용하는 것이 좋습니다.
Multi level Cell 이란 한 Cell에 여러개의 bit를 저장하는 것이죠.
또 Cell을 3차원으로 적층하여, 용량을 효율적으로 쓰는 방식도 존재합니다.
NAND Flash 메모리는 어떻게 HDD처럼 Logical Block으로 바꿔줄 수 있을까요?
일단 세 가지 독특한 점을 정리하자면
- Read Write Erase라는 독특한 연산이 있다
- Read Write는 Page단위로 Erase는 Block 단위로 이루어진다
- Erasure의 최대 횟수가 곧 수명이다
가 있고, 이를 고려하여 Flash Translation Layer가 별도의 하드웨어로 이를 맡습니다.
그 알고리즘에 대해서는 우리가 이제 알아보아야 하고요.
Direct Mapping을 사용하는 것은 어떨까요?
Directed Mapped FTL이 바로 이 방식입니다.
그냥 한 블록 내부에 있는 Page를 순서대로 0,1,2...,n 이렇게 Mapping해주는 것이죠.
그렇게 되면 N번째 Lgical Block을 읽는 것은, Physical Page N을 읽으면 되기 때문에 쉽죠.
그렇지만 Write 문제에 있어서 이것은 복잡해집니다
- N 번째 Logical Block이 Mapped되어 있는 Flash Page의 Flash Block을 전부 읽는다
- Flash Block을 전부 지운다
- 읽은 내용에 새로운 내용을 더해서 Block전체를 다시 쓴다
이러면 Write amplication 문제가 발생합니다.
Page 사이즈보다 작은 데이터를 계속해서 쓰게 된다면, Flash memory가 빠르게 wear out되고 성능이 빠르게 저하됩니다.
Write amplication에 대해서 자세히 알아볼까요?
저희가 02번 페이지에 Z를 쓰고 싶다고 가정합시다. 그렇다면 Block내에 소속된 데이터를 전부 DRAM으로 옮겨야 합니다.

그리고 그 블록 전체에 대해 Erasure를 실행 합니다

그 후 DRAM에 있는 정보를 Block 0에 써 줍니다.

일정 Data를 쓰기 위해서 4배에 달하는 DATA를 지워야 했죠?
이를 바로 Write amplication이라고 합니다.

다른 방법은 없을까요?
현대 아키텍쳐에서는 log structured FTL이라는 것을 사용합니다. 여기엔 중요한 두 컨셉트가 있습니다.
- Logging
- N번째 Logical block을 쓰게 될때 free 되어 있는 Page에 쓰게 됩니다.
- Mapping table
- N번째 Logical block에 뭔가를 쓰려면 그것이 어디에 기록되어 있는지 계속 관리해야 하기 때문에 Mapping table을 계속해서 저장합니다.
- Mapping table은 DRAM에 저장됩니다 (SSD에도 함께)
그럼 어떻게 정보를 저장하는지 한번 볼까요?
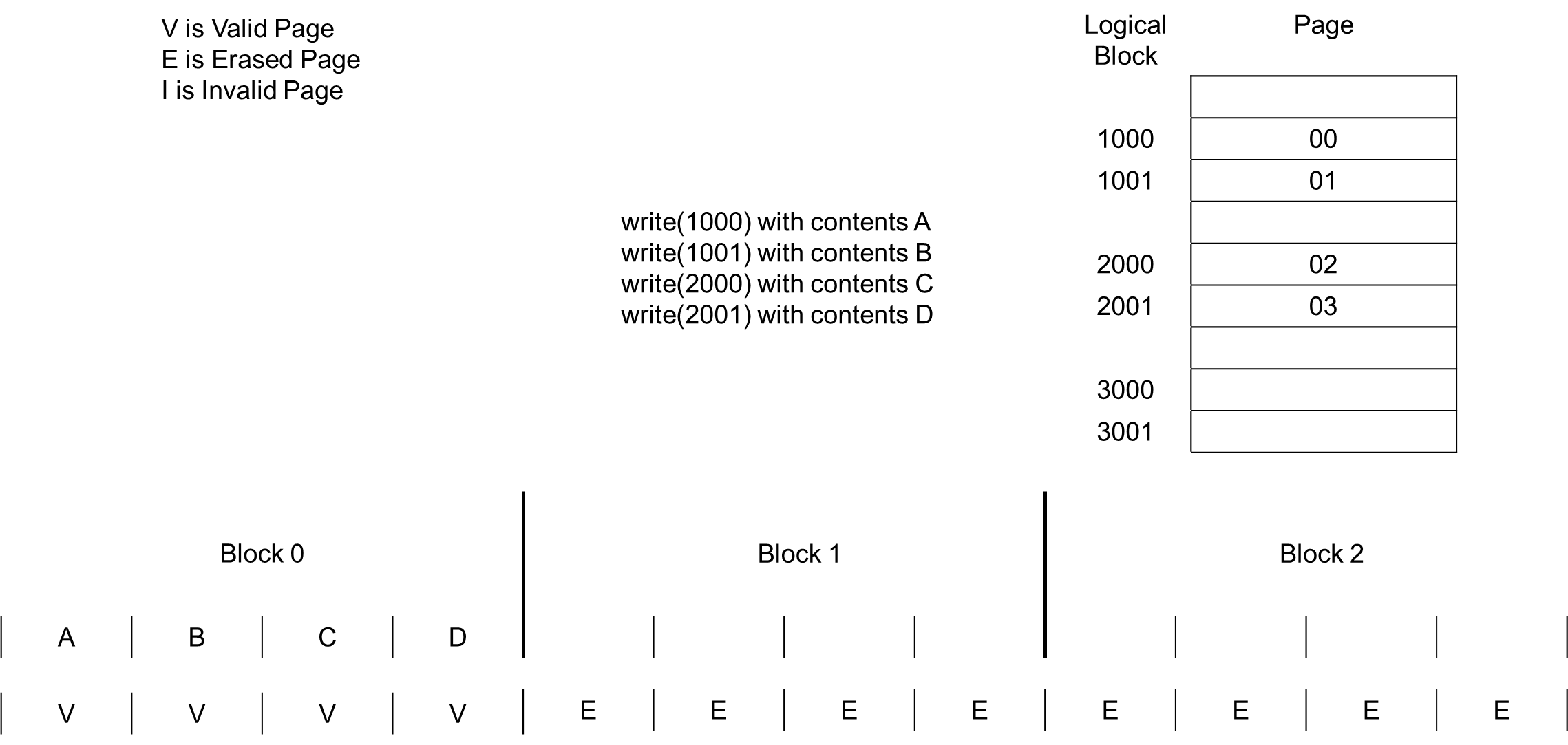

이렇게 계속해서 Appending 하며 데이터를 씁니다.
그런데 Invalid 한 data가 눈에 띄죠? 그 부분에 대해서는 Garbage Collection을 해줍니다.
Garbage Collection은 다음과 같이 이루어 집니다.
- Block a의 Valid한 Page를 DRAM에 복사하기
- 비어 있는 Block b에 Write해 주기
- Block 0을 지우기
- Mapping Table Update 하기
이렇게 되면 WAF는 매우 많이 감소하겠죠?
하지만 이 방식에도 단점이 있습니다. 첫째로, Garbage collection이 매우 큰 Overhead가 되기 때문이죠.
GC는 특정 데이터를 읽고, 지우고, 다시 써 주는 과정을 포함하기 때문에 Overhead가 매우 큽니다.
GC는 남는 시간에 Invalid page들을 쓰고 다시 지우는 과정을 반복합니다.
그래서 GC 때문에, 최대한 남는 블록을 먼저 사용하고 그 다음에 GC를 실행하게 됩니다.
둘째로는 , Mapping Table이 생각보다 크다는건데 이는 대략 1TB의 SSD중 1GB를 사용하게 됩니다.
SSD는 워낙 크니 문제가 없지만, DRAM에 이걸 올리는 과정 때문에 문제가 발생할 수 있겠죠.
이것의 해결 방법으로는 Demand-based FTLs 가 있는데, 이 방식은 Mapping Table 전체를 DRAM에 올리는 것이 아니라 일부 자주 사용되는 것들만 DRAM에 올리는 방식입니다.
이것은 Locality 덕분에 작동하게 되는데 이럴 경우 장점은 DRAM을 적게 사용한다는 점이지만, 단점은 Performance가 Random일 경우 매우 성능이 나쁘고 DRAM에 없을 경우 다시 찾아서 올려줘야 하기 때문에 High Miss penalty가 발생합니다.
SSD가 균일하게 쓰이도록 하려면 어떻게 해줘야 할까요?
그런데 아까 NAND Flash memory는 수명이 존재한다고 말씀드렸죠?
Erasure을 할 수 있는 최대치가 존재하기 때문이죠, 기본적으로 Log Structure FTL은 GC를 통해서 wear- leveling 을 지원하지만 이게 고르지 않을 수도 있어요.
어떤 블록은 Long live Data가 살고 있어서 Cold Page가 되어 남은 수명이 길 수 있고
어떤 데이터는 자주 데이터가 바뀌어서 Hot Page가 되어 더 낮은 수명을 가질 수도 있겠죠
그래서 Wear - Leveling을 해주는 다른 메소드를 사용하여 균일하게 수명을 갖도록 도와줘야 합니다.
- Dynamic Wear leveling
- 이럴 경우 이미 데이터가 저장된 블록에 대해서는 관리하지 않고, 데이터를 새로 쓸때 남는 Space중 수명이 긴 것 부터 사용하게 만드는 방식을 씁니다.
- (+) 오버헤드가 낮고, 적용하기 쉽습니다.
- (–) 이미 잘 변하지 않는 데이터가 저장된 블록에 대해서는 관리가 어렵습니다.
- 이럴 경우 이미 데이터가 저장된 블록에 대해서는 관리하지 않고, 데이터를 새로 쓸때 남는 Space중 수명이 긴 것 부터 사용하게 만드는 방식을 씁니다.
- Static Wear leveling
- Erase가 잘 안되는 블록에 저장된 데이터를 다른 블록으로 계속 옮겨줍니다.
- (+) 잘 변하지 않는 데이터가 저장된 블록도 관리할 수 있습니다.
- (–) 이것 역시 추가적인 Wear-Out이기 때문에 오히려 수명을 낮추는 방식이 될 수 있습니다.
- Erase가 잘 안되는 블록에 저장된 데이터를 다른 블록으로 계속 옮겨줍니다.
적절히 erasure의 총합이 너무 높아지지는 않으면서, 균등하게 관리될 수 있도록 해 주어야 겠죠?
'컴퓨터 > 운영체제' 카테고리의 다른 글
| File System Implementation (0) | 2021.12.12 |
|---|---|
| I/O , File 과 Directory 측면에서 (0) | 2021.12.10 |
| HDD란? (0) | 2021.12.09 |
| I/O Devices (0) | 2021.12.09 |
| Free Space Management (0) | 2021.12.08 |



